微信API-Gateway流控和缓存功能解析
简介
随着WXBot的微服务化,在WXBot后端实际上独立出了数十个微服务,并且微服务的数量在持续上升。这些微服务目前日均调用量有数千万到数亿次。 这些微服务都需要有鉴权、流控、缓存和监控等功能。我们希望将这些功能放在API-Gateway中统一实现。同时因为目前QPS在一万左右,该API-Gateway的响应性能也至关重要。
因为API-Gateway本质上要解决的问题是一个高IO,高并发,低计算的工作。Go的性能不错,且开发效率相对高,人力储备也相对充足,因此最终决定使用Golang开发API-Gateway。
目前接入了API-Gateway的微服务有机器翻译,QA,分词,NER(命名实体识别),知识图谱,文章分类等服务。
架构解析
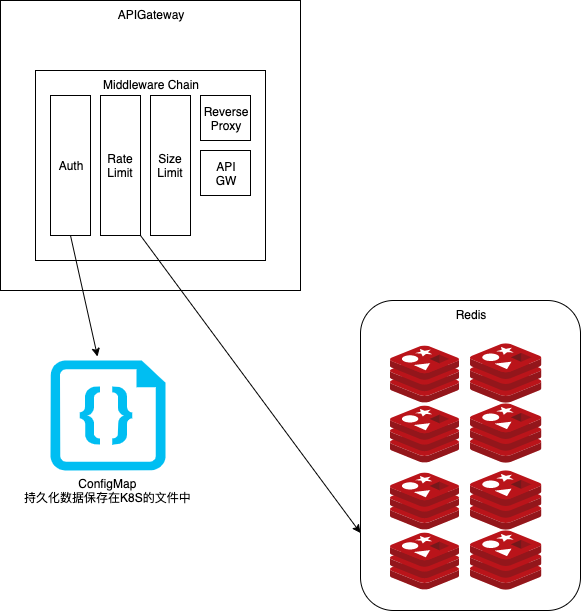
整个API-Gateway是基于调用链的,会链式调用Auth,Rate Limit, Size Limit,Cache(可选),Reverse Proxy等组件。
Auth的实现目前基于ConfigMap,我们将用户信息全部配置在ConfigMap里,原因是因为我们部署基于Kubernetes,所以可以非常简单的广播配置文件。又因为,我们的用户或者需要持久化的数据,显然不会非常多(例如,用户数估计短期内不会上千)。而用文件做持久化,速度更快,开发更简单。更容易保证不掉QPS的要求。
SizeLimit本身没有什么好说的,如果Request的Size超出了预定的Size就直接拒绝请求。
Reverse Proxy目前支持三种逻辑,RoundRobin、Random和User-hash:
- RoundRobin方式会在后端的backend上顺序依次转发请求
- Random方式在后端的backend里随机取一个转发请求
- User-hash方式根据request里的User name hash出一个hash值来选定后端backend,这种方式可以保证相同用户的请求可以一直转发到后端的同一个backend
Rate Limit和Cache的实现方式会在后文详细说明。
流控功能
限流算法
限流算法一般来说有以下几种:
漏桶算法
令牌桶算法
漏桶(Leaky Bucket)算法思路很简单,水(请求)先进入到漏桶里,漏桶以一定的速度出水(接口有响应速率),当水流入速度过大会直接溢出(访问频率超过接口响应速率),然后就拒绝请求,可以看出漏桶算法能强行限制数据的传输速率。因为漏桶的漏出速率是固定的参数,所以,即使网络中不存在资源冲突(没有发生拥塞),漏桶算法也不能使流突发(burst)到端口速率。因此,漏桶算法对于存在突发特性的流量来说缺乏效率。
令牌桶算法(Token Bucket)和 Leaky Bucket 效果一样但方向相反的算法,更加容易理解。随着时间流逝,系统会按恒定1/QPS时间间隔(如果QPS=100,则间隔是10ms)往桶里加入Token(想象和漏洞漏水相反,有个水龙头在不断的加水),如果桶已经满了就不再加了,新请求来临时,会各自拿走一个Token,如果没有Token可拿了就阻塞或者拒绝服务。
多后端限流池
限流的工程本质是多个分布式计数器字典:
- Key: 是需要限流的特征Key。
- 比如 : 某一个API,某一个用户,某一个IP下,每分钟限流100次,那么Key可以是
{API}_{USER}_{IP}。
- 比如 : 某一个API,某一个用户,某一个IP下,每分钟限流100次,那么Key可以是
- Value: 是目前的已调用次数,或者剩余的可调用次数。
所以,简单的用 Key做一个哈希,可以很容易的分派给多后端。
实现
我们最后采取了基于Redis的限流算法:
- Key:
{API与用户融合的字符串}_{当前分钟数} - Value: 目前的调用次数。
1 | key = f"{key}_{min}" |
举个例子,比如我们使用的Key为zA21X31,过期时间设为59秒,限流速率为20 Req/min。
| Redis Key | zA21X31:0 | zA21X31:1 | zA21X31:2(超限) | zA21X31:3 | zA21X31:4(超限) |
|---|---|---|---|---|---|
| Value | 3 | 8 | 20 | >2 | 20 |
| Expires at | Latest 12:02 | Latest 12:03 | Latest 12:04 | Latest 12:05 | Latest 12:06 |
| Time | 12:00 | 12:01 | 12:02 | 12:03 | 12:04 |
简单来说就是使用Redis计算每分钟的单个用户在特定api发送的Request数,如果少于limit就计数,如果大于等于limit就拒绝该请求的服务。
我们的算法类似于漏桶算法,使用令牌桶算法能够可以比较平滑的限流,但是考虑到有单点故障的隐患(比如增加计数的进程挂了),以及部署起来略微复杂,所以采用了当前算法。
针对部分服务的优化
像机器翻译服务这类的服务,每个request包含的翻译语句长度不一,而后端翻译服务处理请求的时间和句子的长度成正相关的关系,因此不能简单地以每分钟的Request数来限流。
所以针对机器翻译服务,我们将计数器每次加的值改成了HTTP Request中payload数据成员的长度,payload即用户希望翻译的句子经过base64编码的字符串。
这种解决方式给Request存在权重问题的情景给出了一种统一的解决方案。从广泛的角度来说,我们可以把这种Request不平均的问题抽象成一个权重,在机器翻译服务是句子的长度,在别的场景可能是另外的权重,可以由后端服务的开发者来定义,计数器每次加这样一个权重值来进行限流以解决不均衡问题。
缓存功能
动机
以机器翻译服务为例,其本身是个幂等性的服务,即翻译前后语句的对应关系保持不变,因此可以考虑将此映射存在缓存里,缓存里有的话直接从缓存里拿,没有的话再去请求后端服务,为后端服务减轻负担,并且同时可以减少Request的响应时间,提高性能。
实现
我们采用了基于Redis的Key-Value对来存放映射关系:
- Key:对于每个服务的每个句子有一个独立的key,考虑到用户针对不同场景可能需要不同的缓存,因此添加了一个extrakey字段给用户自己定义
- apiName+extraKey(用户自定义字段)+Payload(翻译之前的句子)
- Value:翻译之后的句子
其实实现很简单,可以用伪代码表示如下:
1 | Key = Serialize(apiName,extraKey,Payload) |
其中Cache不命中之后,再往缓存存key-value对的逻辑,不影响主逻辑的进行,因此可以放入Go协程中进行,可以压缩掉一个请求存数据库的时间。
考虑到Redis是基于内存的存储,使用起来成本比较高,因此我们实现了基于Redis和SSDB的两种版本。SSDB是一个高性能的支持丰富数据结构的 NoSQL 数据库,用于替代 Redis。它能够达到Redis的100倍容量,并且兼容了Redis的API。它将热点数据放在内存中,其余的数据放在硬盘。
几个需要注意的问题
缓存的命中率,缓存命中率与TTL有关,TTL的时间越长则缓存的命中率越高,但是相对来说就越占空间。因此选择一个合适的过期时间是比较tricky的事情,要在后续的实际应用中验证。目前我们的缓存过期时间设定的是7天。
缓存的失效,比如后端机器翻译服务的model更新了,在目前的实现里缓存的数据并不会实时失效或者更新。一种解决方式是设定一个trigger,每次更新model之后自动将缓存清空。
SSDB的Key有长度限制,需要小于等于100。这个问题可以用hash去解决,把Key映射为一个hash值来解决这个问题,但是会存在hash碰撞的情况,如果hash函数设置的足够好,碰撞的概率是极其低的。另外也有几种解决思路,比如从业务需求的角度来讲,Key的长度大于100是不是合理的,长度不符合要求的请求是可以在size limit那层过滤掉的。除此之外也可以重新编译SSDB的源码,改动它对Key的长度限制,以使之符合要求。
总结
我们对API-Gateway中基于Redis的限流算法做了详细的说明,并且针对特定的后端服务做了一层缓存,实现了基于Redis和SSDB的两个版本。限流和缓存这两块的功能已经稳定,未来应该不会再有大的变化。本工作在josephyu的指导下进行,感谢josephyu。